Ilastik
Note
Any image analysis tool may be used to generate the segmentations as long as they meet the requirements of the Nutil software.
This section describes the use of ilastik for the QUINT workflow. Find ilastik user documentation and download here. RRID:SCR_015246.
Iiastik is a supervised machine learning tool that supports feature extraction by segmentation.
The segmentations from ilastik are 8-bit PNG images that appear black in appearance. They should not be used directly in Nutil.
To make them compatible with Nutil, apply the Glasbey lookup table with a tool such as FIJI. This applies constrasting RGB colours to the different classes, which visualises the labels, allowing a validation step prior to quantification.
Instructions for how to do this are found below.

Preparing images for ilastik
Image size
As a general rule, the histological images should be downscaled before segmenting with ilastik. This improves the output quality and speeds up the analysis.
The resize factor will depend on the original size of the images and the size of the features to be extracted. It is determined by trial and error. The Pixel Classification algorithm extracts image pixels based on their colour, intensity and / or texture on a scale up to 10 sigma. This means that the algorithm recognises edges or objects that fall within a 10 x 10 pixel window. For the best result, resize the images so that the objects (for example, cells) fall within this window, but without loss of important information (for example, smaller cells). A resize factor of 0.2 or 0.1 is a good starting point.
File format
Ilastik supports many file formats. PNG works well. It does not support tiled TIFFs.
Tip
Nutil supports resizing of images, renaming and file format conversion and is specifically designed for histological images from mouse and rat.
Segmentation with ilastik
There are two main approaches for segmentation with ilastik.
Pixel classification only (with two or more classes)
Pixel classification with two classes (immunoreactivity and background), followed by object classification with two classes (objects e.g. cells and artefact).
Which approach is best?
The best approach depends on the appearance of the labelling in the images and is determine by trial and error.
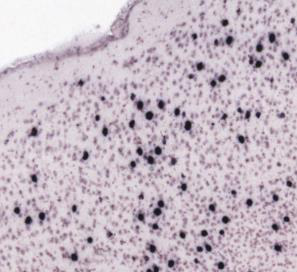
The first approach is quick and easy, and is the method of choice as long as it gives satisfactory output. It is best for images where there are clear differences in the colour, intensity and / or texture of the features (for example, labelled cells) relative to the background and other structures. For example:
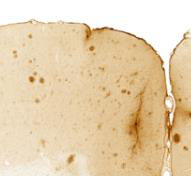
The second approach is more time consuming, but may give better results if there is non-specific labelling that has a similar appearance to the labelling-of-interest. This is because the Object Classification Workflow can filter out non-specific labelling based on object level features such as size and shape. An example is cells and edge staining of similar colour and intensity, that are both extracted by Pixel Classification, but have different object shapes and so are easy to differentiate with Object Classification (“round” cells versus “long and thin” edge staining). For example:
1. Pixel Classification Workflow
For a quick introduction, watch:
Open the ilastik programme. Under ‘Create New Project’ select ‘Pixel Classification’. Save the project under a new file name in the same location as the images for analysis (create a new folder).
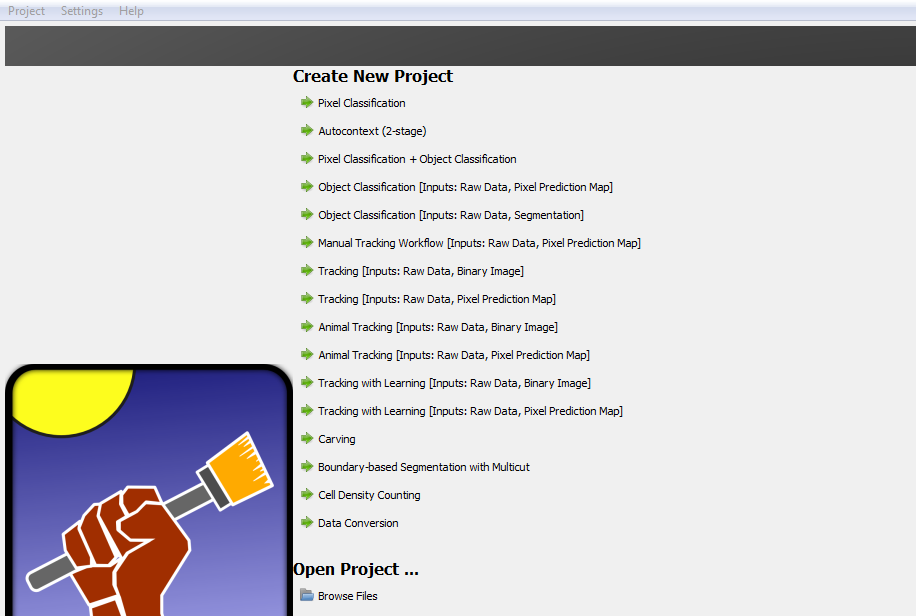
On the left hand side of the screen there are five input applets.
In the Input data applet, select ‘Add New’. Add one or more images for the purpose of training the classifier (training images). Convert the format of the images to HDF5 to increase the processing speed. To do this, highlight the uploaded images, select ‘storage’ and change from ‘relative link’ to ‘copied to project file’. Save the project.
Select the Feature Selection applet and click ‘Select Features’.

Select the features and scales that can be used to discern the objects or classes of interest: for most datasets, all the features should be selected. See FAQ for advice on selecting good features.
Select the Training applet. To scroll around the image, press shift and use the mouse wheel to navigate. To zoom, press ctrl and use the mouse wheel to zoom in and out. Click ‘add label’ to create two or more classes. See FAQ for advice on the number of classes to use.
Label some example pixels of each class with the paintbrush, and remove labels with the eraser. Select ‘live update’ to begin the machine learning and prediction process. Turning on the uncertainty overlay, by clicking on the uncertainty eye, will help in the labelling process as it identifies pixels of which ilastik is unsure of the class. By correctly labelling these pixels, the prediction rapidly improves. See FAQ for advice on placing labels.
The ‘probability’ and ‘segmentation’ overlays should be turned on to inspect the final result.
On completion of training, select the Prediction Export applet. Export “probability maps” in HDF5 format, and “simple_segmentation” images in 8-bit PNG format in turn, with the default settings. Do not alter the export location. The files will automatically save in the same location as the input files.
The files can either be exported individually by clicking the export button in the Prediction Export applet, or in batch (see step 9).
For batch processing of images with the trained classifier, select the Batch Processing applet. Upload the images to be analysed, and select ‘process all files’. The time taken to process the files will depend on the size and number of files selected.
Save the ilastik file before closing.
Note
Save the ilastik file frequently during the annotation process.
2. Object Classification Workflow
There are three options on the ilastik start up page for running Object Classification. Choose the Object Classification with Raw Data and Pixel Prediction Maps as input. It is not advisable to use Pixel Classification + Object Classification. This file type is easily corrupted.
Save the object classification file in the same folder as the raw images for analysis. If the images are moved after the ilastik file is created, the link between the ilastik file and the images may be lost, resulting in a corrupted file.
In the Input Data applet, upload the original images and their respective probability maps in HDF5 format (output from the pixel classification).
4. In the Threshold and Size Filter applet, select: * The simple method. * The input channel that corresponds to the label of interest. * Smoothing factor for the x and y axis. In general, the same value should be selected for each. Determine the most appropriate factor by trial and error: the goal is to achieve object shapes that are most representative of the real data. Zero is often advisable – in which case no smoothing filter is applied. * Threshold. The probability threshold can range from 0 to 1: with zero representing no exclusion of pixels; and 1 representing exclusion of all pixels except those with 100% probability of belonging to the class-of-interest. In reality only the pixels that were manually annotated in the Pixel Classification workflow have a 100% probability of belonging to the class-of-interest. A good compromise is 0.4.
In the Object Feature Selection applet, select all the features (except those relating to location within the image).
In the Object Classification applet, create two classes (label and artefact) and label some example objects of each class. Tick the live update box. Continue annotating until you are happy with the predictions.
In the Object Information Export applet, export “Object Predictions” in 8-bit PNG format. Do not change the default export location.
For batch processing, use the Batch Processing applet. Upload the raw images and corresponding prediction maps and “process all files”.
3. Applying the Glasbey Lookup table
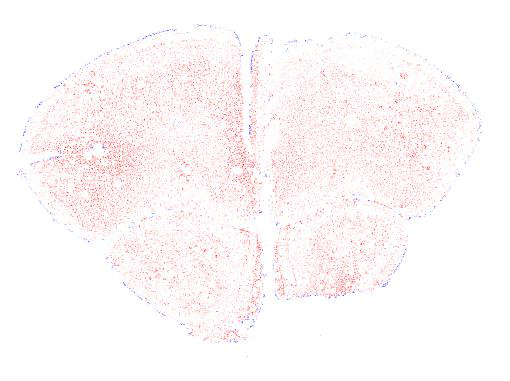
The 8-bit PNG output from ilastik are black or white in appearance. This is because similar shades of black or white are assigned to the classes. To visualise the results, and make them more compatible with Nutil, apply the Glasbey lookup table (LUT) with NIH ImageJ / FIJI.
Download the NIH ImageJ / FIJI tool.
Open the image: it appears black (or white).
Apply the Glasbey LUT by selecting Image > Lookup Tables > Glasbey. This assigns a different colour to each label.
Save the image in PNG format. They are now compatible with Nutil Quantifier.
Customise the LUT
In some cases you may wish to alter the applied colours. To do this, select Image > Color > Edit LUT. The LUT applies colours from the top left hand corner (first colour is not used). Click on each colour to alter it. Then Save the customised LUT and save the image in PNG format.
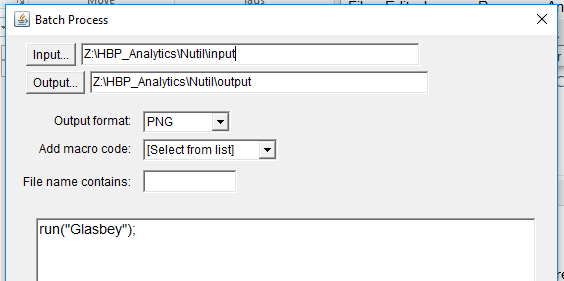
Batch processing: Apply the Glasbey LUT to a folder of images
To apply the Glasbey lookup table to a whole folder of segmented images, select:
Process >Batch> Macro; select the input and output folders, required file type, and type the following code in the macro box: run(“Glasbey”);
|
2. To apply the customized LUT to a folder of images, first save the customized LUT as a .LUT file. Apply to a whole folder of images with the Batch Processing feature. Select: Process > Batch > Macro. Select the input and output directories and output format PNG, and type the following macro:
open(“C:\……\….\….\filename.lut”);
Note
Make sure to update the directory so it locates the customized.lut file, and ensure the macro is written with double back slashes.
FAQ and troubleshooting
1. Which pixel classification features should I select?
The features and scales to select are those that distinguish the different classes in the image. As it is not always obvious which features and scales distinguish the classes, it is best to select all the features and scales for the pixel classification in the first instance. Selecting fewer features and scales may speed up the analysis, so refining the selection may be helpful at a later stage.
Note that the scale corresponds to the pixel diameter of the feature. For example, if a textural pattern has a pixel size of 4, the scale of the texture has a sigma of 4. As the maximum scale of the features available in ilastik is 10, ilastik is not capable of recognising objects based on edge if the objects are larger than approximately 60 pixels (the whole object should be visible in 10 x 10 pixel window).
2. Which images should I upload in the Input Data applet?
Only training images should be uploaded in the Input Data applet (~10 is good).
3. What are training images?
Training images are a subset of the whole image series that you annotate in the training phase. Choose images that contain labelling that is representative of the labelling in the whole series. It is good to select images that span the full volume, as labelling often varies in different anatomical regions (for example, every 4th section). The same subset can be used for the pixel and object classification workflows.
4. How many classes should I use?
The number of classes to annotate will depend on the classification approach. * For Pixel Classification only, create two or more classes. As a general rule, the fewer the better. * For Pixel Classification with Object Classification, annotate two classes in each classification step.
5. Which part of the image, and how much, should I label?
Start by zooming-in and annotating a few pixels of each class that clearly belong to their respective class. Turn on the ‘live update’ to view the predictions. The ‘uncertainty’ overlay can be switched on to identify pixels with uncertain class prediction (it identifies these pixels in bright blue). By annotating these pixels, the prediction quickly improves.
Note that even just a few incorrectly annotated pixels can disrupt the prediction. If in doubt, it is better to delete annotations and start again, rather than continuing with the annotation. By ticking the ‘segmentation’ box you can view the final segmentation based on the classifier. When you are happy with this, stop annotating and test the trained classifier on the next training image.
6. How do I test the trained classifier on the other images in the series?
To test the ability of the trained classifier to segment a new image, select ‘current view’ in the Training applet and choose a new training image from the drop-down menu. Press ‘live update’ and view the ‘segmentation’ overlay. If you are not happy with the classification you can annotate pixels on the new image to improve the prediction. When satisfied with the result, the trained classifier can be tested on a third image. Continue this processes until you are satisfied that the classifier is optimally trained for the image series. You are now ready for batch processing.
7. Which export settings should I select?
The file type to export will depend on the plan for the next step of analysis.
In the Pixel Classification workflow, export Simple_Segmentation.PNG to visualize the segmentation, or Prediction_maps.H5 to continue with Object Classification.
In the Object Classification workflow, export Object_Predictions.PNG.
The PNG images should be export as unsigned 8-bit images.
Do not alter the output location. The default export location is the folder in which the ilastik file is located. If the output location is altered, the file will fail to export. This is a bug in the system!
8. Help! ilastik keeps crashing. I have very large images. What do I do?
While ilastik has the computational power to process very large images, the viewer in the ilastik user interface is not able to process whole images that are very large in the “live” mode. For large images in the training phase, it is therefore important to remain zoomed-in in the viewer when the live update is switched on. This is especially true if many classes are labelled and many features selected. As a general rule of thumb, keep the portion of the image that is visible in the viewer to below 3000 x 3000 pixels. The absolute value will depend on the number of classes and features selected.
For very large images, be more selective with the features for classification, and label as few classes as possible.
If all else fails, it is possible to split large images into tiles and process tiles individually. These have to be stitched before continuing with the QUINT workflow.
Note that exportation of the segmented images will take time. One large image (e.g. 30,000 x 30,000 pixels) may take 2 hours to export. Image analysis can be run overnight in the batch mode.